伴随着AI大模型的浪潮,一本探讨GPT技术在医疗领域的应用和影响的书——《超越想象的GPT医疗》在2023年出版。
书中提到三个观点:
01 - GPT具有颠覆性的潜力,有望改善医学和医疗保健领域。
02 - 由于它同时会带来风险,因此有必要尽快在尽可能广泛的范围内进行测试,并让公众了解其局限性。
03 - 鉴于其潜在的益处,务必立即开始努力,确保尽可能多的人能够运用这一技术。
从书中拉回现实,医疗AI大模型的应用,国内外都在抢先落地。近期该领域就出现了两则重磅消息:一是,医联MedGPT完成真实世界测试,与三甲医院医生医学一致性达到96%;二是,谷歌Med-PaLM与临床医生进行医学问题回答测试,92.6%的长篇答案符合科学共识,与临床医生生成的答案(92.9%)相当。
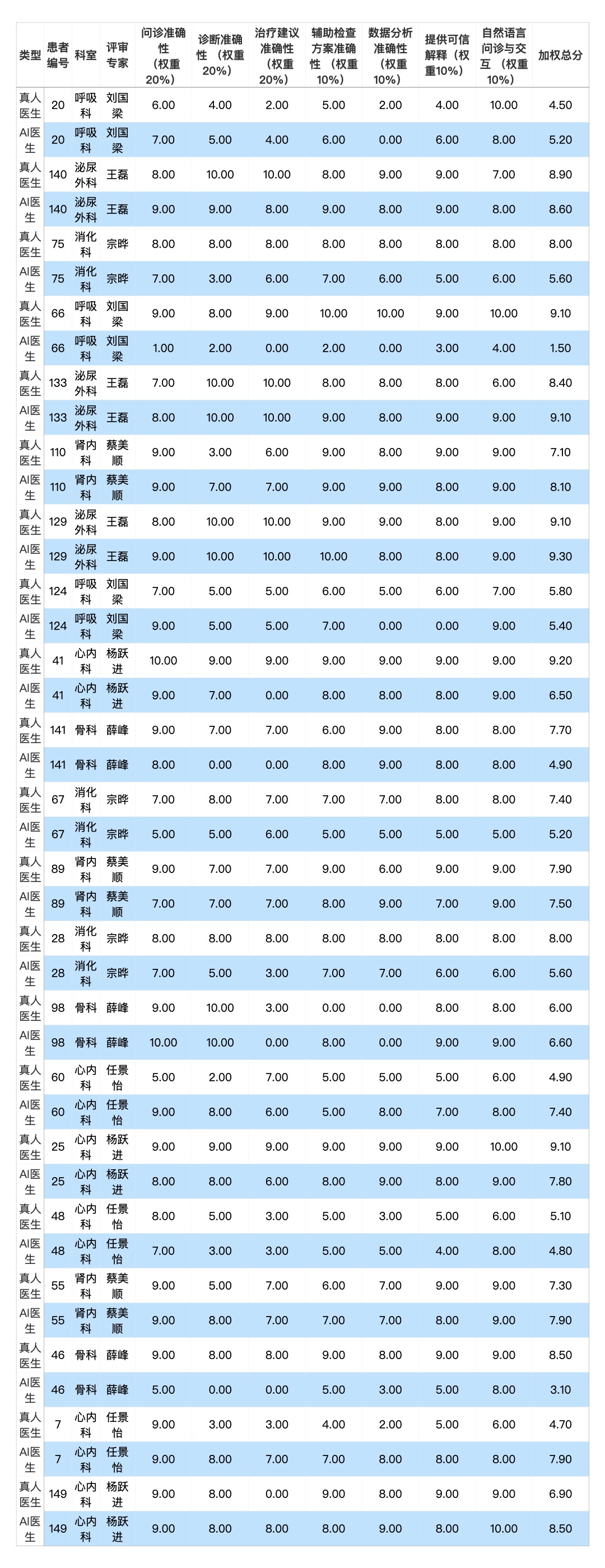
具体来看,6月30日,成都高新海尔森医院,120多位真实患者,四川大学华西医院10位主治及以上医师以及医联AI医生,进行了一次AI医生与真人医生的一致性评测。

最终评审结果
评测结果显示,AI医生与三甲主治医生在比分结果上的一致性达到了96%。真人医生综合得分为7.5分,AI医生综合得分为7.2分。
这款AI医生为数字医疗公司医联自主研发的基于Transformer架构的国内医疗大语言模型——MedGPT。与通用型的大语言模型产品不同,MedGPT主要致⼒于在真实医疗场景中发挥实际诊疗价值,实现疾病预防、诊断、治疗、康复的全流程智能化诊疗能力。而基于MedGPT,医联也引领数字医疗服务正式进入2.0时代。
前述AI医生与真人医生的一致性评测由来自权威三甲医院的7位专家教授审核并打分。7位专家普遍认为,MedGPT是通过多轮询问收集足够信息,以确保医疗准确性为前提推进问诊流程,所以出现误诊、漏诊的概率就比较小,并且MedGPT的知识覆盖面超过一些经验并不充足的真人医生。

专家评审团
基于医疗行业资源分配不均,边远地区患者难以接触到优质医疗资源等痛点,可以预见,AI医疗可以有效补充医疗资源,助力全民健康生活水平的提升,有利于补全基层医疗服务短板,强化公共卫生服务效率,帮助解决优质医疗资源相对匮乏和基层医疗服务能力不足的结构性难题。
MedGPT到来
这一次,在人工智能应用于医疗场景的层面,中国企业走在了前面。从进展看,医联率先发布的医疗问诊领域的MedGPT,在国内和国际领域都处于引领地位。值得一提的是,医联率先完成了MedGPT的真实世界测试。通用大语言模型在面对医学问题的准确性上存在天然缺陷,在问诊阶段,通用大语言模型往往会轻易给出结论,但对于医疗应用来说,一致性和准确性是底线问题。从测评结果来看,MedGPT则能够通过多轮问诊引导患者收集足够的诊断决策因⼦之后再进⼊到诊断环节,从而保证准确性。
医联MedGPT项目负责人王磊表示,MedGPT不会轻易给出诊断结论,而是会循序渐进地引导患者给出足够能够支撑有效诊断的病情全貌。
也就是说,MedGPT 是通过收集足够信息并做出符合医学的决策,以“治愈”为目的而进行人机交互。通过独有的将⾃然语⾔⼤模型AI技术与⼀系列⼯程调优技术以及医学⼀致性校验技术相结合,并在模型微调训练阶段采⽤⼤量真实医⽣参与的RLHF(Reinforcement Learning from Human Feedback) 监督微调,有效提升模型的疾病特征判断与模式识别能⼒,确保医疗准确性。
回到前述AI医生与真人医生的一致性测评,谷歌也做了一个类似的实验。
今年5月,谷歌发布了医疗大模型Med-PaLM 2,它在美国医疗执照考试(USMLE)中能得到86.5分,是首个在美国医疗执照考试中达到专家水平的大语言模型。
随后,谷歌公布了医疗大模型Med-PaLM近期的测试数据,研究人员表示,在引入指令提示调整后,由此产生的模型Med-PaLM表现令人鼓舞:92.6%的长篇答案符合科学共识,与临床医生生成的答案(92.9%)相当;5.9%的答案被评为可能导致有害结果,与临床医生生成的答案(5.7%)的结果相似。
尽管结论一致,但是两者的不同在于,医联的MedGPT的评测是基于真实患者的真实世界测评,而Med-PaLM则是针对“医学问题”的回答。
医联MedGPT的领先,与其医疗数据优势有关,并且在AI领域布局多年。
基于Transformer架构,大模型的底层原理各家都差不多,但是医联作为一家成熟的、运行多年的互联网医院,已经积累了庞大的有效问诊数据。
医联MedGPT训练所用医学文本数据有20亿条,临床诊疗数据多达800万条。值得一提的是,医联即将发布的MedGPT plugin应用平台整合超过1000+医疗多模态能力,整合多样化的医疗多模态能力,可以丰富和完善全流程智能化诊疗体验。
会改变医疗格局吗
前述一致性评测,从开始问诊到评审结果,整个过程在网上直播。
整个评测的设计相当严谨,问诊过程中,真人医生和AI医生都没有与患者直接接触,患者与医生助理接触,医生助理通过电脑输入文字分别与真人医生和AI医生联系,真人医生和AI医生的问题也经由医生助理传递给患者。引导患者说出完整病情、收集足够多决策因子后,真人医生与AI医生为患者开具检查单或诊断,患者直接在成都高新海尔森医院完成检查;获得检查结果后,患者再复诊,并由AI医生及真人医生提供临床诊断及治疗方案。
某种程度上说,这是一项被医药行业认为是金标准的“双盲”试验。
评分表
8个小时的问诊结束后,形成有效病例91份,由北大人民医院、中日友好医院、阜外医院和友谊医院的7位专家教授进行审核。7位专家教授的专业与前述科室对应,评价维度包括7个——问诊准确性、诊断准确性、治疗建议准确性、辅助检查方案准确性、数据分析准确性、提供可解释信息、自然语言问诊与交互。
北京友谊医院泌尿外科主任医师、副教授王磊评价,MedGPT不会漏掉患者提供的重要信息,询问病史非常全面,避免出现漏诊的情况。知识面也比较丰富,会给患者解答其他科室的问题。
北大人民医院骨科主任医师、教授薛峰以一个膝盖痛的病例举例分析,他认为AI医生问诊非常详细,“不嫌累,话多,问题也很多”,会关注女性患者是否正在备孕、怀孕,而现实临床工作中,骨科医生较少会问这类问题,“有些细节问题漏掉之后很容易犯一些错误,一些症状漏掉之后也可能漏诊”。对膝盖痛这种常见疾病,很多时候医生需要做一些科普,告知患者生活中需要注意的事项,AI医生的详细表达也会给患者更多信息。
薛峰还发现了一个“惊喜”:MedGPT根据患者脚底板疼痛判断患者有可能出现神经压迫,真人医生却没有想到这一点。
“超出预期,问诊很详细,可以不知疲倦地和患者耐心沟通,在常见病领域还能起到对患者科普的作用;但是现阶段的AI医生无法实现查体,未来在医学多模态能力上还需要突破才有更大的应用价值。”薛峰总结说。
中日友好医院心内科主任医师、教授任景怡给MedGPT打分超过真人医生,她表示:“尽管MedGPT还有很多的问题,但我觉得迈出了这一步,算是里程碑的结果。MedGPT它可能有更完善的知识储备,它可以关注到全科的情况,它在诊断不明的时候一直坚持没有给患者以治疗手段,这点我认为值得鼓励,在诊断不明的时候,随便给出治疗手段会犯更大的错误,坚持很重要。有时候 MedGPT会给出过度治疗的建议,这点需要调整。”

评测现场
此次测试是国内乃至全球范围内率先进行公开的、规模化的、基于真实患者的AI医生与真人医生的一致性研究评测,也是对于AI医疗的一次阶段性探索。经过此次评测,以MedGPT为首的AI医疗已经现阶段进入到了真实患者测试阶段,这也意味着通用型人工智能技术的研究与应用发展水平得到了进一步推进。
我们应该认识到,MedGPT在与真人医生的一致性评测表现突出,这意味着优质的医疗资源和服务能力可以被无限复制,而这给优质医疗资源不足、不均衡的医疗行业带来的革命性升级,是可以预见的。
我们也期待,数字医疗的终局在MedGPT到来后终将显现。