译者 | 朱先忠
审校 | 重楼
在本文中,我们将探讨如何将策略梯度强化学习应用于A/B优化。本文将给出一个观察策略梯度方法的简单演示;其中,我们将深入了解有关潜在的机制,并逐步可视化学习过程。
简介
与监督、自监督和无监督学习一样,强化学习是机器学习的一个基本概念。在强化学习中,主体试图在环境中找到一组最佳的动作,以最大限度地获得奖励。强化学习作为一种可以在围棋和国际象棋中击败最优秀棋手的方法,与神经网络作为高度灵活的代理相结合,已经广为人知。
其中,用作代理的神经网络能够通过使获得的奖励最大化来逐步学习优化策略。目前,人们已经开发了几种策略来更新神经网络的参数,例如策略梯度、q学习或ActorCritic(演员-评判家)学习。其中,策略梯度方法最接近反向传播,它通常用于神经网络的监督和自监督学习。然而,在强化学习中,我们并不像在监督学习中那样直接评估每个动作,而是试图最大化总回报,并让神经网络决定要采取的个人动作。这个动作是从概率分布中选择的,这为进一步探索提供了高度的灵活性。在优化开始时,操作是随机选择的,代理探索不同的策略。随着时间的推移,一些行动被证明比其他行动更有用,概率分布最终表现为明确的决策。与其他强化学习方法不同,用户不必控制探索和开发之间的这种平衡,最佳平衡是由梯度策略方法本身找到的。
通常,使回报最大化的最佳策略是通过一系列行动来实现的,其中每个行动都会导致环境的新状态。然而,梯度策略方法也可以用来寻找在统计上给予最高奖励的最佳行动。在执行A/B优化时经常会发现这种情况,这是一种非常常见的从两个选项中选择其一的更好的技术。例如,在市场营销中,A/B测试用于选择能带来更高销售额的广告方案。你更愿意点击哪个广告?选项A:“充分利用您的数据:我是一名专业的数据科学家,我可以帮助您分析您的数据”或选项B“与您的数据作斗争?专业数据分析师可以免费帮助您自动化数据分析”?

两个广告创意选项。你更愿意点击哪一个?(图片由作者创作)
A/B优化的困难在于点击率是可变的。例如,在网站上看到广告后,每个用户可能有不同的偏好,处于不同的情绪中,因此反应也不同。由于这种可变性,我们需要统计技术来选择更好的广告方案。比较选项A和B的常用方法是假设检验,如t检验。要进行t检验,广告的两个潜在版本必须显示一段时间,以收集用户的点击率。为了对优选的广告方案进行显著的评估,需要相当长的探索时间,其缺点是潜在的收入损失,因为在探索过程中,更好和更差的广告同样频繁地随机显示。通过尽快更频繁地显示更好的广告来最大限度地提高点击率是有利的。通过使用梯度策略方法执行A/B优化,代理将首先随机探索变体A和变体B,那个将获得更高的广告奖励,从而导致更高的点击率,因此代理将很快学会更频繁地向用户展示更好的广告,并最大化点击率和收入。
实例展示
在我们的例子中,我们有两个广告创意选项,其中我们假设选项A的点击概率为30%,选项B的点击概率是40%。我们开展了一场广告活动,有1000个广告印象。如果我们只进行探索,并且同样频繁地显示这两个选项,我们可以预期平均点击率为35%,总共平均点击350次。如果我们知道B会被更多地点击,我们只会显示B,平均点击400次。然而,如果我们运气不好,选择只显示A,我们平均只能获得300次点击。我们稍后将更详细地探讨策略梯度方法,我们可以实现平均391次点击,这清楚地表明,快速应用学习到的策略会导致点击次数几乎与我们最初选择更好的选项B一样高。
运行机制解析
我们使用TensorFlow库在小型神经网络上使用梯度策略方法运行A/B优化。首先,我们需要导入一些第三方库。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf神经网络只包含一层,由一个神经元决定播放哪一则广告。由于我们没有关于用户偏好、位置、时间或其他任何信息,因此决策是基于对神经网络的零输入,并且我们不需要使用大型神经网络所实现的非线性。训练是通过调整这个神经元的偏置来实现的。
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Dense(1, activatinotallow="sigmoid", input_shape=(1,)))
model.summary()我们编写了一个函数,它用于使用神经网络选择动作,显示选项A或选项B。该函数使用tf.function()进行修饰,它创建了一个静态计算图,使其运行速度比在Eager模式(走一步看一步,能够立即输出结果)下快得多。通过使用TensorFlow的GradientTape函数,我们在广告选择过程中收集梯度。每次用户进入网站时,神经网络都会产生一个输出,该输出被视为选择要呈现给用户的广告变体A或变体B的概率。
由于我们只有一个神经元具有S形激活,因此输出是0到1之间的单个数字。如果输出为0.5,则有50%的机会显示广告B,并且有50%的可能性显示广告A。如果输出为0.8,则显示广告B的可能性为80%,显示广告A的可能性为20%。通过将神经网络的输出与0和1之间的均匀分布的随机数进行比较来选择动作。如果随机数小于输出,则动作为True(1),并且选择广告B;如果随机数大于输出,则操作为False(0),并选择广告A。损失值使用binary_crosentropy_loss测量神经网络的输出和所选动作之间的差。然后,我们创建相对于模型参数的损失梯度。
@tf.function()
def action_selection(model):
with tf.GradientTape() as tape:
output = model(np.array([[0.0]])) # [0 ... 1]
action = (tf.random.uniform((1, 1)) < output) # [0 or 1]
loss = tf.reduce_mean(tf.keras.losses.binary_crossentropy(action, output))
grads = tape.gradient(loss, model.trainable_variables)
return output, action, loss, grads我们进行了超过1000次广告展示的训练。在每个步骤中,广告都会出现一次,新用户有机会点击广告。为了评估学习过程,我们统计这段时间后的点击总数。学习率定义为0.5。我们稍后将讨论学习率对总点击次数的影响。
STEPS = 1000
LR = 0.5现在,让我们来做广告宣传。随着时间的推移,神经网络将改进其预测能力。通过强化学习,训练和应用同时发生。在实践中,选择的广告现在显示在网站上,我们必须等待,看看用户是点击了广告还是没有点击就离开了网站。在代码中,我们只是模拟用户是否点击。如上所述,广告A被点击的概率为30%,而广告B被点击的概率为40%。点击可以直接作为训练神经网络的奖励来处理。奖励用于修改梯度。如果用户点击了广告,则该动作的梯度保持不变,但如果用户没有点击广告,则梯度反转。最后,梯度下降通过给神经网络分配新的权重和偏差值来更新神经网络的参数。
for step in range(STEPS):
output, action, loss, grads = action_selection(model)
if action == False: # Action A
reward = float(np.random.random() < 0.4)
if action == True: # Action B
reward = float(np.random.random() < 0.5)
grads_adjusted = []
for var_index in range(len(model.trainable_variables)):
grads_adjusted.append((reward-0.5)*2 * grads[var_index])
model.trainable_variables[0].assign(model.trainable_variables[0]-LR*grads_adjusted[0])
model.trainable_variables[1].assign(model.trainable_variables[1]-LR*grads_adjusted[1])下图总结了学习过程的演变。
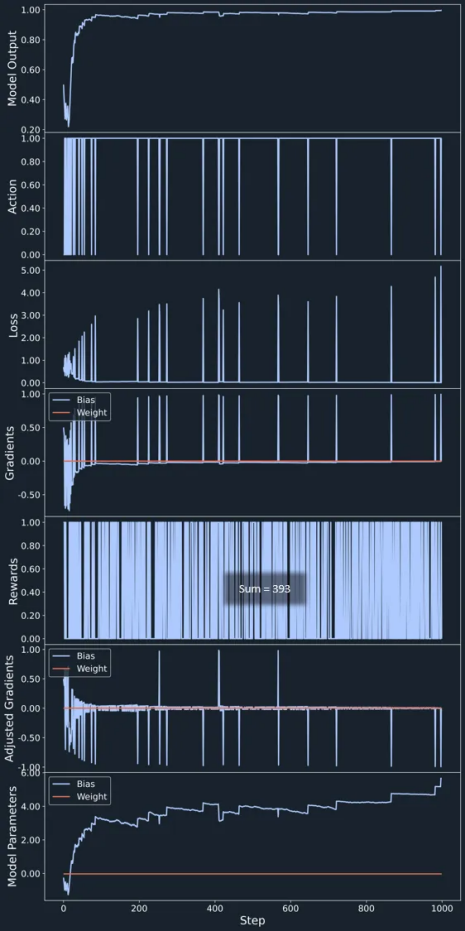
使用策略梯度强化学习的A/B优化学习过程的演变。(图片由作者创作)
总的来说,上图中显示的1000个广告印象的活动总共导致了393次点击,这相当接近400次——这个数字等于如果我们只选择更好的广告B时我们期望的点击次数。
我们首先通过观察初始步骤=1的所有图表来回顾学习过程。我们观察到,神经网络输出从0.5开始,导致广告B和广告A分别以50%的概率随机选择广告。binary_crosentropy_loss测量模型输出和所采取的行动之间的差异。由于动作要么是0要么是1,因此初始损失值是模型输出0.5的负对数,约为0.7。由于我们的神经网络中只有一个神经元,因此梯度包含该神经元的权重和偏差的两个标量值。如果选择广告A,则偏置的梯度为正数,如果选择广告B,则偏置梯度为负数。权重参数的梯度总是零,因为神经网络的输入是零。奖励是高度随机的,因为广告被点击的几率只有30%-40%。如果点击广告,我们会得到奖励,梯度不变;否则,我们会反转梯度。将调整后的梯度乘以学习率,并从神经网络的初始参数中减去。我们可以看到,偏置值从零开始,当施加正调整梯度时变得更负,而当施加负调整梯度时则变得更正。
在广告活动期间,神经网络的输出倾向于1,增加了广告B被选中的机会。然而,即使模型输出已经接近1,显示广告A的机会仍然很小。随着模型输出接近1,如果选择动作B,则损失值很小,并且我们获得了小的负梯度,但在选择广告A的罕见情况下,获得了更大的损失值——表现为偶尔的峰值和大的正梯度。在收集奖励之后,可以观察到这些正峰值中的一些在调整后的梯度中被反转,因为这些动作没有导致点击。由于广告B具有更高的点击概率,较小的负调整梯度比源于广告A上的点击的正梯度更频繁地应用。因此,模型的偏差值以小的步长增加,并且在广告A被选择和点击的罕见情况下,偏差值减小。模型的输出由应用于模型偏置值的S形函数提供。
学习率的影响
在这个演示中,我们观察到,神经网络可以学会从两个选项中选择更好的选项,并更频繁地应用该选项以最大限度地提高回报。在这种设置下,平均将获得391次点击,其中广告A的点击概率为30%,广告B的点击几率为40%。在实践中,这些概率会低得多,它们之间的差异可能更小,这使得神经网络更难探索更好的选择。
政策梯度法具有自动调整勘探与开发之间平衡的优点。然而,这种平衡受到学习率的影响。更高的学习率将导致更短的探索阶段和更快的学习策略应用,如下图所示,其中学习率从0.01提高到10。在100个个体广告中平均得到的模型输出随着学习率的增加而更快地增加,学习率高达1。然而,在较高的学习率下,存在适应错误动作的风险,只有在短暂的探索期内,错误动作才会表现得更好。在高学习率下,模型输出调整过快,导致决策不稳定。
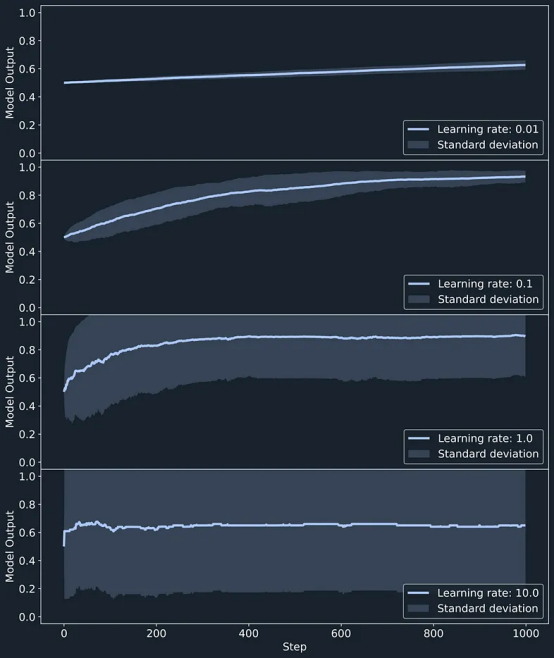
学习率对神经网络输出的影响。(图片由作者创作)
因此,有一个最佳的学习率可供选择,这在实践中可能很难找到,因为事先对点击概率一无所知。将学习率从0.01变化到10.0表明,对于0.1到2.0之间的学习率,获得了点击总次数的最大值。更高的学习率显然会增加标准差,这表明学习过程的不稳定性,也会导致平均点击量的减少。
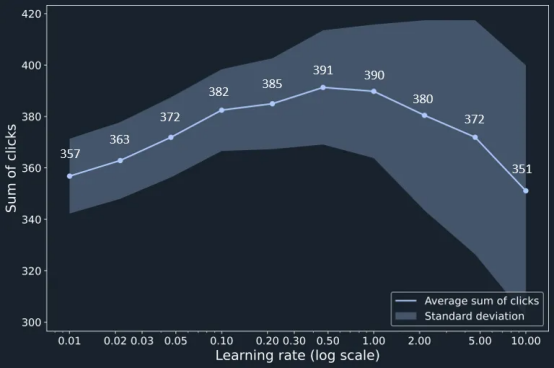
学习率对广告活动期间获得的总点击量的影响。(图片由作者创作)
总结
本文示例程序演示了如何将强化学习用于A/B优化。这仅仅是一个简单的例子,用于说明策略梯度方法的基本过程。然后,我们已经了解了神经网络如何根据所选广告是否被点击来基于调整后的梯度更新其参数。快速应用学习到的策略可最大限度地提高点击率。然而,在实践中,选择最佳学习率可能很困难。
最后,您可以在huggingface.co网站上找到本文示例工程完整的代码和流媒体演示:https://huggingface.co/spaces/Bernd-Ebenhoch/AB_optimization。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:A/B Optimization with Policy Gradient Reinforcement Learning,作者:Dr. Bernd Ebenhoch
链接:
https://towardsdatascience.com/a-b-optimization-with-policy-gradient-reinforcement-learning-b4a3527f849