在人工智能蓬勃发展的今天,想了解它的原理似乎不是一件容易的事儿。其实它的核心问题仍然是数学,而且并不复杂,会比你想象的简单得多。如果你登过山(在山间迷路更佳),那么你就能理解它的底层策略。
本文来自微信公众号:返朴 (ID:fanpu2019),作者:乔丹·艾伦伯格,编译:胡小锐、钟毅,原文标题:《如果你爬过山,怎会不了解机器学习?》,题图来自:《银翼杀手2049》
我的朋友梅瑞迪斯·布鲁萨德(Meredith Broussard)是纽约大学的一位教授,她的专业研究领域是机器学习及其社会影响。不久前,她接受了一项任务:用大约两分钟的时间在电视上向全美观众解释人工智能的定义及其工作原理。
她向采访她的主持人解释说,人工智能不是杀手机器人,也不是智力让人类相形见绌但没有感情的人形机器人。她告诉主持人:“我们只需要记住一点,它的基本原理就是数学,没什么可怕的!”
主持人痛苦的表情暗示了,他们宁愿谈论杀手机器人。
但梅瑞迪斯的回答一语中的。既然我不用遵守两分钟的时间限制,就让我接过这项任务,解释一下机器学习的数学原理吧,因为这个“伟大的创意”比你想象的要简单。
机器学习如登山
假设你不是一台机器,而是一名登山者,正在努力地往山顶爬。但你没带地图,四周又都是树木和灌木丛,也没有什么有利位置能让你看到更广阔的风景。那么,你该如何登顶呢?
有一种策略是,评估你脚下的地面坡度。当你往北走的时候,地面坡度可能会略微上升,当你往南走的时候,地面坡度可能会略微下降。当你转向东北方时,你发现那里有一个更陡峭的上坡。你在一个小圈里走来走去,勘察了你可能前往的所有方向,并发现其中一个方向的上坡是最陡峭的,于是你朝那个方向走了几步。然后,你再画一个圈,并从你可能前往的所有方向中选出最陡峭的上坡,以此类推。
现在,你知道机器学习的工作原理了吧。
好吧,也许还不止这些,但这个叫作“梯度下降法”(Gradient descent)的概念是机器学习的核心。它其实是一种试错法:你尝试一堆可能的行动方案,然后从中选出最有助于你摆脱困境的那个。与某个方向相关的“梯度”是一个数学概念,它是指“当你朝那个方向走一小步时,高度会发生多大的变化”,也就是你走的那条路的地面坡度。梯度下降法是一种算法,它利用数学语言制定了“一条明确的规则,告诉你在你可能遇到的各种情况下应该怎么做”。
这条规则是:考虑你可以朝哪些方向走,找出其中梯度最大的那个,并朝那个方向走几步;重复上述步骤。
把你前往山顶的路线绘制到地形图上,大致的样子如图1所示。
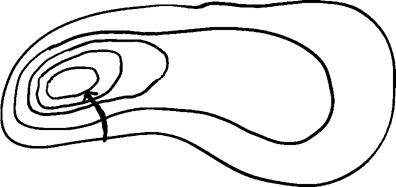
图1 这又是一个很棒的几何图形。当你利用梯度下降法来指引方向时,你在地形图上的路线必定与等高线垂直。
但它与机器学习又有什么关系呢?
假设我不是一名登山者,而是一台尝试学些东西的计算机,例如阿尔法围棋或GPT-3(能生成一长串看似合理且令人不安的英语文本的人工智能语言模型)。但一开始,先假设我是一台尝试学习猫是什么的计算机。
我该怎么做?答案是:采取类似于婴儿的学习方法。在婴儿生活的世界里,经常有大人指着他们视野中的某个东西说“猫”。你也可以对计算机进行这样的训练:给它提供1000幅猫的图片,这些猫的姿态、亮度和情绪各不相同。你告诉计算机:“所有这些都是猫。”事实上,如果你真想让这种方法行之有效,就要另外输入1000幅非猫的图片,并告诉计算机哪些是猫而哪些不是。
机器的任务是制定一个策略,使它能够自行区分哪些是猫而哪些不是。它在所有可能的策略之间徘徊,试图找到最好的那个,即识别猫的准确度达到最高。它是个准登山者,所以它可以利用梯度下降法确定行进路线。你选择了某个策略,将自己置于对应的环境中,然后在梯度下降规则的指引下前行。想一想你对当前策略可以做出哪些小改变,找出能为你提供最大梯度的那个,并付诸行动;重复上述步骤。
贪婪是相当好的东西
这句话听起来颇有道理,但随后你会发现自己并不明白它的意思。例如,什么是策略?它必须是计算机可以执行的东西,而这意味着它必须用数学语言来表达。对计算机而言,一幅图片就是一长串数字。如果这幅图片是600×600像素的网格,那么每个像素都有一个亮度,它们的值在 0(纯黑)到 1(纯白)之间。只要知道这 36 万(600×600)个数字,就能知道这幅图片是什么内容了。(或者,至少知道它的黑白图像是什么样子。)
策略是一种将输入计算机的 36 万个数字转变成“猫”或“非猫”(用计算机语言来说就是“1”或“0”)的方法。用数学术语来表达的话,策略就是一个函数。事实上,为了更贴近心理现实,策略的输出可能是一个介于 0 和 1 之间的数,它代表了当输入是一幅模糊的猞猁或加菲猫枕头图片时,机器可能想表达的不确定性。当输出是 0.8 时,我们应该将其解读为“我几乎可以肯定这是一只猫,但仍心存疑虑”。
例如,你的策略可能是这样一个函数:“输出你输入的 36 万个数字的平均值”。如果图片是全白的,函数给出的结果就是 1 ;如果图片是全黑的,函数给出的结果就是 0。总的来说,这个函数可以测量计算机屏幕上图片的总体平均亮度。这跟图片是不是猫有什么关系?毫无关系,我可没说它是一个好策略。
我们如何衡量一个策略是否成功呢?最简单的方法是,看看那台已学习过2000幅猫和非猫图片的计算机接下来的表现。对于每幅图片,我们都可以给策略打一个“错误分数”【现实世界中的计算机科学家通常称之为“损失”(error or loss)】。如果图片是猫且策略的输出是 1,那么错误分数为0,也就是说答案正确。如果图片是猫而策略的输出是0,那么错误分数为 1,这是最坏的一种可能。如果图片是猫而策略的输出是0.8,那么答案近似正确但带有些许不确定性,错误分数为0.2。(衡量错误程度的方法有很多种,这里说的并不是实践中最常用的那种,但它更易于描述。)
把用于训练的所有2000幅图片的错误分数加总,就会得到总错误分数,它可以衡量你的策略是否成功。你的目标是找到一个总错误分数尽可能低的策略,怎样才能让策略不出错呢?这就要用到梯度下降法了,因为现在你已经知道策略随着你的调整而变得更好或更差意味着什么。梯度测量的是,当你对策略稍做改变时错误分数的变化幅度;在你能对策略做出的所有小改变中,选出可使错误分数下降幅度最大的那个。梯度下降法不仅适用于猫,只要你想让机器从经验中习得策略,它就通通适用。
在这里,我不想低估计算方面的挑战。那台学习识别猫的计算机更有可能用数百万幅图片来训练自己,而不只是2000幅。这样一来,计算总错误分数时可能就需要加总100万个错误分数。即使你拥有一台强大的处理器,也需要花不少时间!所以在实践中,我们经常使用梯度下降法的变体之一——随机梯度下降法(Stochastic gradient descent)。
这种方法涉及数不清的微小变化和错误分数,但它的基本理念是:第一步,你从大量的训练图片中随机选择一幅(比如,一只安哥拉猫或一个鱼缸的图片),然后采取可使这幅图片的错误分数降至最低的那个步骤,而不是把所有的错误分数加在一起。第二步,再随机选择一幅图片,重复上述做法。随着时间的推移(因为这个过程要进行很多步),最终所有图片可能都会被考虑到。
我喜欢随机梯度下降法的原因在于,它听上去很疯狂。例如,想象一下,美国总统正在制定全球战略,一群下属围在他身边大喊大叫,建议总统以符合他们自身特殊利益的方式调整政策。总统每天随机选择一个人,听取他的建议,并对政策做出相应的改变。用这种方法管理一个大国是极其荒谬的,但它在机器学习方面却行之有效。
到目前为止,我们的描述缺失了一个重要因素:你如何知道何时该停止呢?你也许会说,很简单啊,当我们做出任何小改变都不能使错误分数降低时,就可以停止了。但有一个大问题:你可能并未真正“登顶”。
如果你是图2中那个快乐的登山者,向左走一步或向右走一步,你会看到这两个方向都不是上坡。这就是你快乐的原因:你自认为已经登顶了!
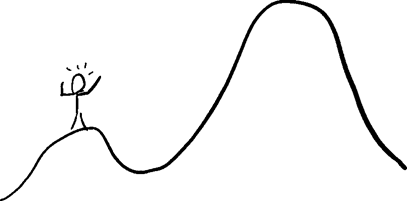
图2
但事实并非如此。真正的峰顶还很遥远,而梯度下降法不能帮你到达那里。你掉进了数学家所说的“局部最优值”(local optimum,局部极大值或局部极小值,它取决于你的目标是冲顶还是触底)陷阱,在这个位置上,任何小变化都不能产生改善效果,但它远非真正的最佳站位。
我喜欢把局部最优值看作拖延症的数学模型。假设你必须面对一项令人厌烦的任务,例如,整理一大摞资料,其中大部分与你多年来一直想达成的目标有关,扔掉它们则代表你最终选择妥协,不打算继续坚持下去了。每一天,梯度下降法都会建议你采取某个小行动,从而最大程度地提升你当天的幸福感。整理那一大摞资料会让你感到快乐吗?不,恰恰相反,它让你感觉很糟糕。推迟一天完成这项任务是梯度下降法对你的要求,第二天、第三天、第四天……算法每天都会给你同样的建议。就这样,你掉进了局部最优值——低谷——的陷阱,要想登上更高的山峰,你必须咬牙穿过山谷,那也许是很长的一段路,而且你得先往下走再往上爬。梯度下降法也被称为“贪婪的算法”,因为它每时每刻都会选择能使短期利益最大化的步骤。贪婪是罪恶之树上的主要果实之一,但有一个关于资本主义的流行说法称“贪婪是好东西”(greed is good)。在机器学习领域,更准确的说法是:“贪婪是相当好的东西。”梯度下降法可能会导致你陷入局部最优值陷阱,但相较于理论层面,这种情况在实践中发生的次数并不多。
想绕过局部最优值,你需要做的就是暂时收起你的贪婪。所有好的规则都有例外。例如,在你登顶后,你可以不停下脚步,而是随机选择另一个地点,重启梯度下降法。如果每次的终点都是同一个地方,你就会更加确信它是最佳地点。在图2 中,如果登山者从一个随机地点开始使用梯度下降法,他就更有可能登上那座大山峰,而不是困在那座小山峰上。
在现实生活中,你很难将自己重置于一个完全随机的人生位置上。更加切实可行的做法是,从你当前的位置随机迈出一大步,而不是贪婪地选择一小步。这种做法通常足以把你推到一个全新的位置上,向着人生巅峰迈进。
我是对还是错?
还有一个大问题。我们愉快地决定考虑所有可能的小改变,看看其中哪一个能带来最优梯度。如果你是一名登山者,摆在你面前的就是一个明确的问题:你在一个二维空间中选择下一步的行动方向,这相当于在指南针上的一圈方向中择其一,而你的目标是找出具有最优梯度的那个点。
但事实上,给猫图片评分的所有可能策略构成了一个十分巨大的无限维空间。没有任何方法能将你的所有选择考虑在内,如果你站在人的角度而不是机器的角度,就会发现这一点显而易见。假设我正在写一本关于梯度下降法的自助类书籍,并且告诉你:“想要改变你的人生,做法很简单。仔细考虑有可能改变你人生的所有方法,然后从中选择效果最好的那个,这样就可以了。”你看完这句话肯定会呆若木鸡,因为所有可能改变你人生的方法构成的空间太大了,根本无法穷尽搜索。
如果通过某种非凡的内省法,你可以搜遍这个无限维空间呢?那样的话,你还会碰到另一个问题,因为下面这个策略绝对可以使你的过往人生经历的错误分数降至最低。
策略:如果你将要做的决策和你以前做的某个决策完全相同,就把你现在考虑的这个决策视为正确的决定。否则的话,抛硬币决定吧。
如果换成学习识别猫的那台计算机,上述策略就会变成:
策略:对于在训练中被识别为猫的图片,输出“猫”。对于被识别为非猫的图片,输出“非猫”。对于其他图片,抛硬币决定吧。
这个策略的错误分数为0!对于训练中使用的所有图片,这台计算机都会给出正确的答案。但如果我展示一幅它从未见过的猫图片,它就会抛硬币决定。如果有一幅图片我展示过并告诉它那是猫,但在我把这幅图片旋转 0.01 度后,它也会抛硬币决定。如果我向它展示一幅电冰箱的图片,它还是会抛硬币决定。它所能做的只是精确地辨识出我展示过的有限的猫和非猫图片,这不是学习,而是记忆。
我们已经看到了策略失效的两种方式,从某种意义上说它们是两个极端。
1. 在你遇到过的许多情况下,这种策略都是错的。
2. 这种策略只适用于你遇到过的情况,但对于新情况它一无是处。
前一个问题叫作“欠拟合”(Underfitting),是指你在制定策略时没有充分利用你的经验。后一个问题叫作“过拟合”(Overfitting),是指你太过依赖自己的经验。我们如何在这两个无用的极端策略之间找到一个折中的策略呢?答案是:让这个问题变得更像登山。登山者搜索的是一个非常有限的选择空间,我们也可以这样,前提条件是我们要对自己的选择加以限制。
我们本能地知道这一点。在思考如何评估自己的人生策略时,我们通常使用的比喻是在地球表面选择方向,而不是在无限维空间中随机游走。美国诗人罗伯特·弗罗斯特将其比作“两条分岔路”。传声头乐队(Talking Heads)的歌曲《一生一次》(Once in a Lifetime)犹如弗罗斯特的诗《未选择的路》(The Road Not Taken)的续作,你仔细品读就会发现,这首歌描绘的正是梯度下降法:
你可能会问自己,那条公路通向哪里?
你可能会问自己,我是对还是错?
你可能会对自己说:天啊!我到底做了什么?
你不必把自己的选择局限于一个旋钮。
而线性回归是选择旋钮的最常用方法之一。当统计学家寻找可根据一个已知变量的值预测另一个变量的策略时,线性回归也是他们的首选工具。例如,一个吝啬的棒球队老板可能想知道,球队的胜率对比赛门票的销量会产生多大的影响。他不想在球场上投入太多的人力物力,除非它们能有效地转化成上座率。
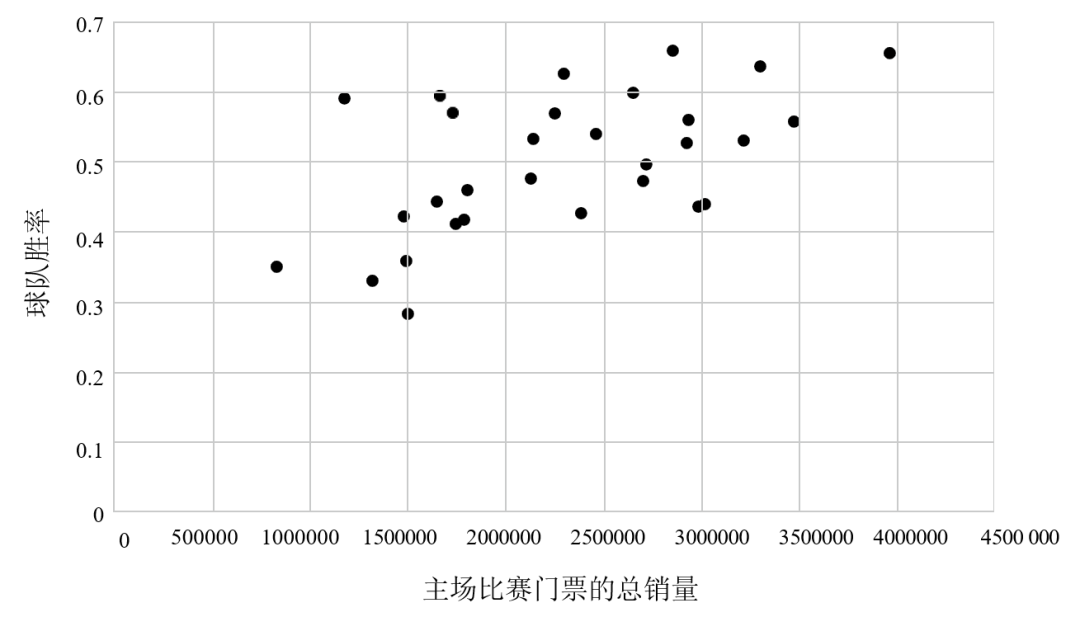
图3 美国职业棒球大联盟2019赛季的主场上座人数 vs 球队胜率
图3上的每个点分别代表一支球队,纵坐标表示这些球队在 2019 赛季的胜率,横坐标表示这些球队的主场上座人数。你的目标是找到一个能根据球队胜率预测主场上座人数的策略,你允许自己考虑的选择空间很小,而且其中的策略都是线性的。
主场上座人数 = 神秘数字 1 × 球队胜率 + 神秘数字 2
任意一个类似的策略都对应着图中的一条直线,你希望这条线能尽可能地匹配你的数据点。两个神秘数字就是两个旋钮,你可以通过上下转动旋钮实现梯度下降,直到你无法通过任何微调降低策略的总体错误分数。(在这里,效果最佳的错误分数是所有球队的线性策略预测值与真实值之差的平方和,所以这个方法通常被称为“最小二乘法”。最小二乘法历史悠久,发展至今已十分完善,用它来寻找最优直线的速度比梯度下降法快得多,但梯度下降法仍行之有效。)
最终,你会得到一条如图4所示的直线。
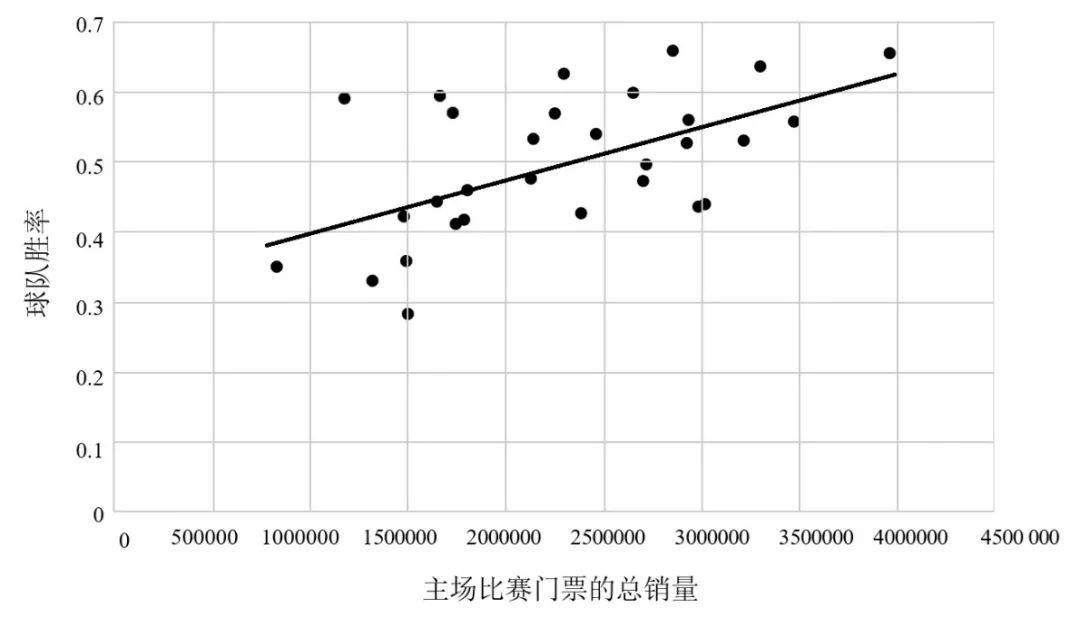
图4
你可能会注意到,即使是错误分数最低的直线,其误差也不小。这是因为,现实世界中的大多数关系都不是严格意义上的线性关系。我们可以试着纳入更多的变量(比如,球队体育场的大小应该是一个相关变量)作为输入来解决这个问题,但线性策略的最终效果仍然有限。例如,这个策略不能告诉你哪些图片是猫。在这种情况下,你不得不冒险进入非线性的狂野世界。
深度学习和神经网络
在机器学习领域,正在研发的一种最重要的技术叫作“深度学习”。它有时以一种先知的姿态出现在人类面前,自动地、大规模地提供非凡的洞见。这种技术还有一个名称——“神经网络”,就好像这种方法能以某种方式自行捕获人类大脑的运行方式一样。
但事实并非如此。正如梅瑞迪斯·布鲁萨德所说,它的原理只是数学,甚至不是最新的数学。这一基本概念早在20世纪50年代末就出现了,从我1985年收到的那堆成人礼的礼物中,你也能看到与神经网络结构类似的东西。除了支票、几个圣杯和20多支高仕笔外,我还收到了父母送的也是我最想要的礼物——雅马哈DX21合成器,它至今还在我的家庭办公室里。早在1985年就能拥有一台合成器,而不是电子琴,这让我感到非常自豪。你不仅能用DX21合成器弹奏出钢琴、小号和小提琴的音色,还可以用它制作你想要的音色,前提是你能掌握那本70页说明书的晦涩内容,其中包含了很多如图5所示的图片。
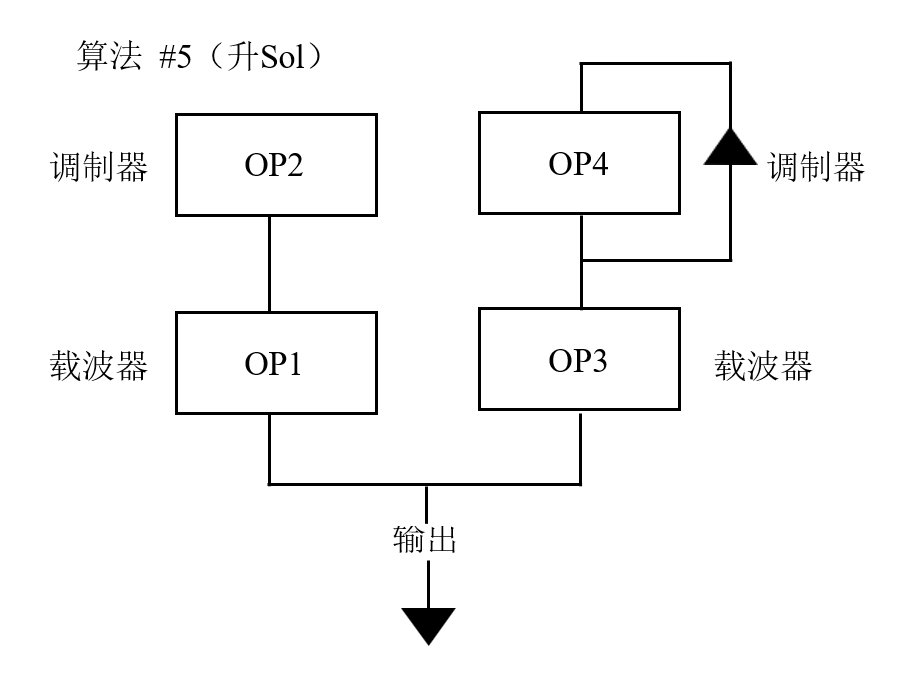
图5
每个“OP”盒子代表一个合成器波,你可以通过转动盒子上的旋钮,让声音变得更响亮、更柔和、随时间淡出或淡入,等等。这些都稀松平常,而DX21真正神奇的地方在于它和操作者之间的连接。图 5 展示了一个鲁布·戈德堡机械式的过程,从OP1发出的合成器波不仅取决于这个盒子上你可以转动的那些旋钮,还取决于OP2的输出。合成器波甚至可以自行调节,附属于OP4的“反馈”箭头代表的就是这种功能。通过转动每个盒子上的几个旋钮,你可以获得范围极其广泛的输出。这给了我尝试的机会,自己动手制作新的音色。
神经网络跟我的合成器很像,它是由几个小盒子构成的网络,如图6所示。
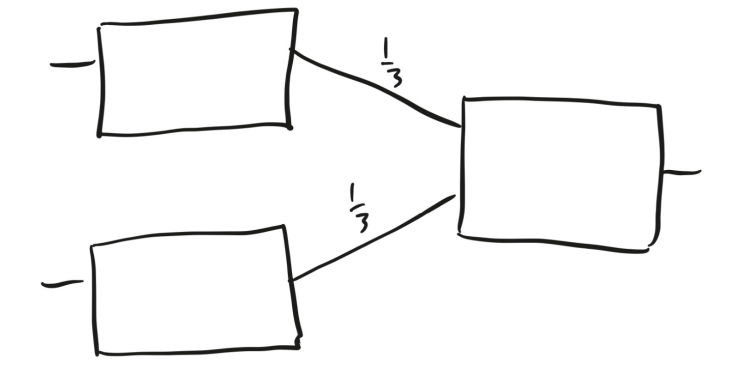
图6
所有盒子的功能都相同:如果输入一个大于或等于 0.5 的数字,它们就会输出1;否则,它们就会输出 0。用这种盒子作为机器学习基本元素的想法,是在1957—1958 年由心理学家弗兰克·罗森布拉特(Frank Rosenblatt)提出来的,他视其为神经元工作原理的一个简单模型。盒子静静地待在那里,一旦接收到的刺激超过某个阈值,它就会发射一个信号。罗森布拉特把这类机器称作“感知机”(Perceptrons)。为了纪念这段历史,我们仍然称这些假神经元网络为“神经网络”,尽管大多数人不再认为它们是在模拟人类的大脑硬件。
数字一旦从盒子中输出,就会沿着盒子右侧的任意箭头运动。每个箭头上都有一个叫作“权重”的数字,当输出沿箭头呼啸而过时,就会乘以相应的权重。每个盒子把从其左侧进入的所有数字加总,并以此作为输入。
每一列被称为一层,图6中的网络有两层,第一层有两个盒子,第二层有一个盒子。你先向这个神经网络输入两个数字,分别对应第一层的两个盒子。以下是有可能发生的情况:
1. 两个输入都不小于 0.5。第一层的两个盒子都输出 1,当这两个数字沿着箭头移动时,都变为 1/3,所以第二层的盒子接收到 2/3 作为输入,并输出 1。
2. 一个输入不小于 0.5,另一个输入小于 0.5。那么,两个输出分别是 1 和 0,所以第二层的盒子接收到 1/3 作为输入,并输出 0。
3. 两个输入都小于 0.5。那么,第一层的两个盒子都输出 0,第二层的盒子也输出 0。
换句话说,这个神经网络是一台机器,它接收到两个数字作为输入,并告诉你它们是否都大于0.5。
图7是一个略显复杂的神经网络。
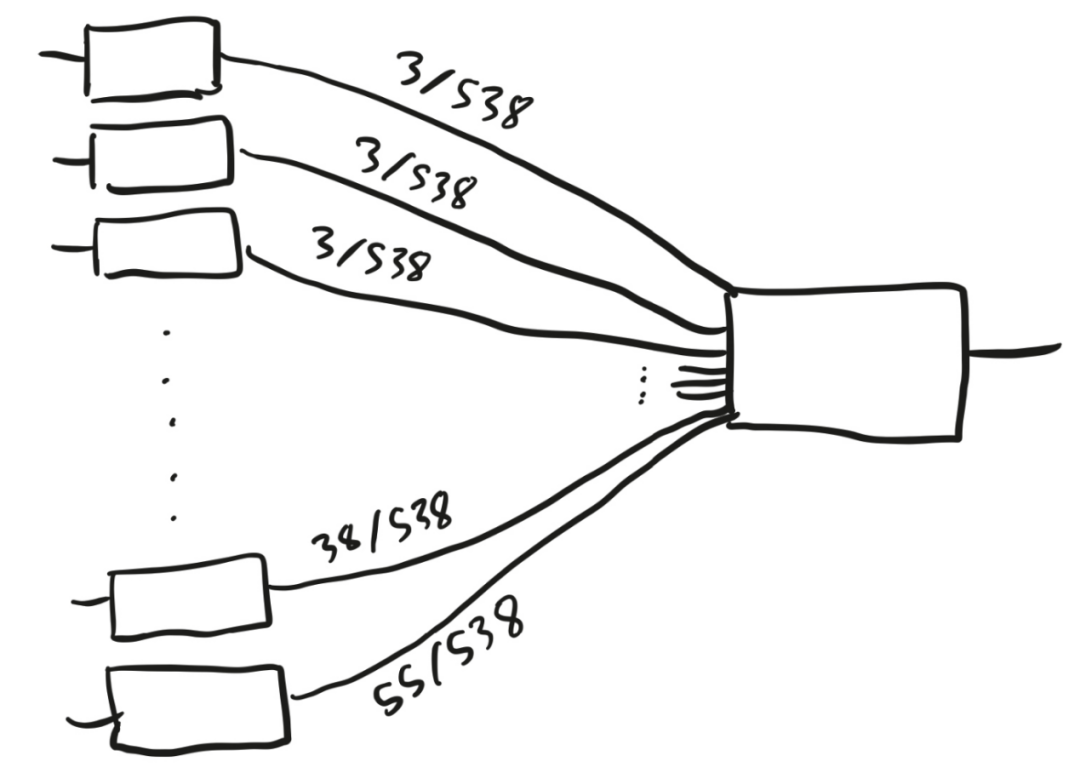
图7
该神经网络的第一层有51个盒子,它们都向第二层的那个盒子输入数字。但箭头上的权重不同,最小的权重为3/538,最大的权重为55/538。这台机器在做什么?它将51个不同的数字作为输入,并激活每个输入大于0.5的盒子。然后,它对这些盒子进行加权计算,检验它们的和是否大于0.5。如果是,就输出1;如果不是,则输出 0。
我们可以把它称作“两层罗森布拉特感知机”,但它还有一个更常用的名称——“选举人团制度”。51个盒子代表美国的50 个州和华盛顿特区,如果共和党候选人在某个州获胜,代表该州的盒子就会被激活。把所有这些州的选举人票数加总后除以538,如果结果大于0.5,共和党候选人就是赢家。
图8是一个更现代的例子,它不像选举人团制度那样易于用语言来描述,但它与驱动机器学习不断进步的神经网络更加接近。
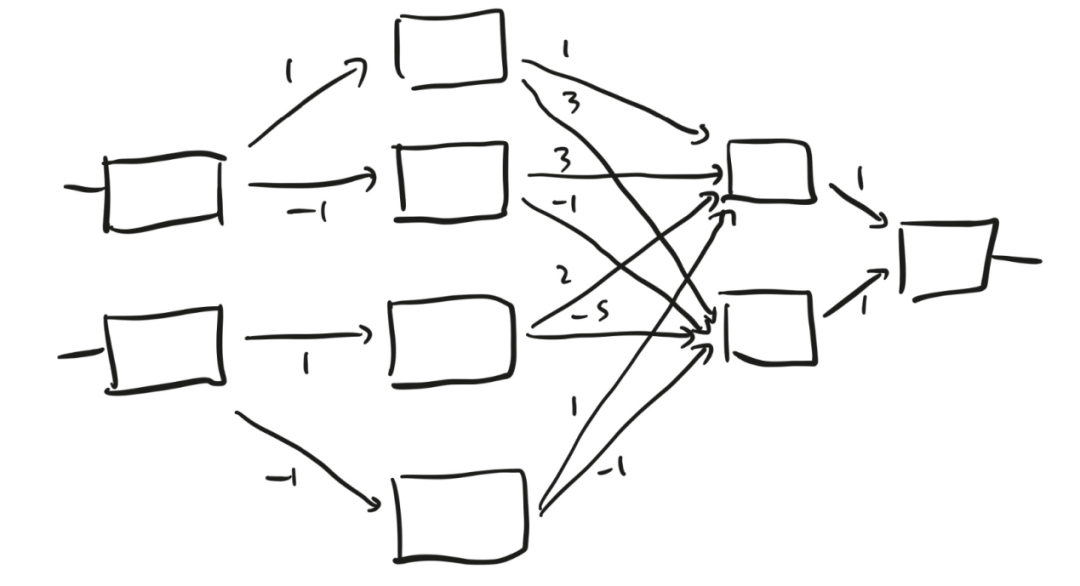
图8
图8中的盒子比罗森布拉特感知机的盒子更精致。盒子接收到一个数字作为输入,并输出该数字和0中较大的那个。换句话说,如果输入是一个正数,盒子就会原封不动地输出这个数字;但如果输入是一个负数,盒子就会输出 0。
我们来试试这个装置(见图9)。假设我先向最左边一层的两个盒子分别输入1和1。这两个数字都是正数,所以第一层的两个盒子都会输出1。再来看第二层,第一个盒子接收到的数字是1×1 = 1,第二个盒子接收到的数字是-1×1 = -1。同理,第二层的第三个盒子和第四个盒子接收到的数字分别是1和-1。1是正数,所以第一个盒子输出1。但第二个盒子接收到的输入是一个负数,未能被触发,所以它输出0。同样地,第三个盒子输出1,第四个盒子输出0。
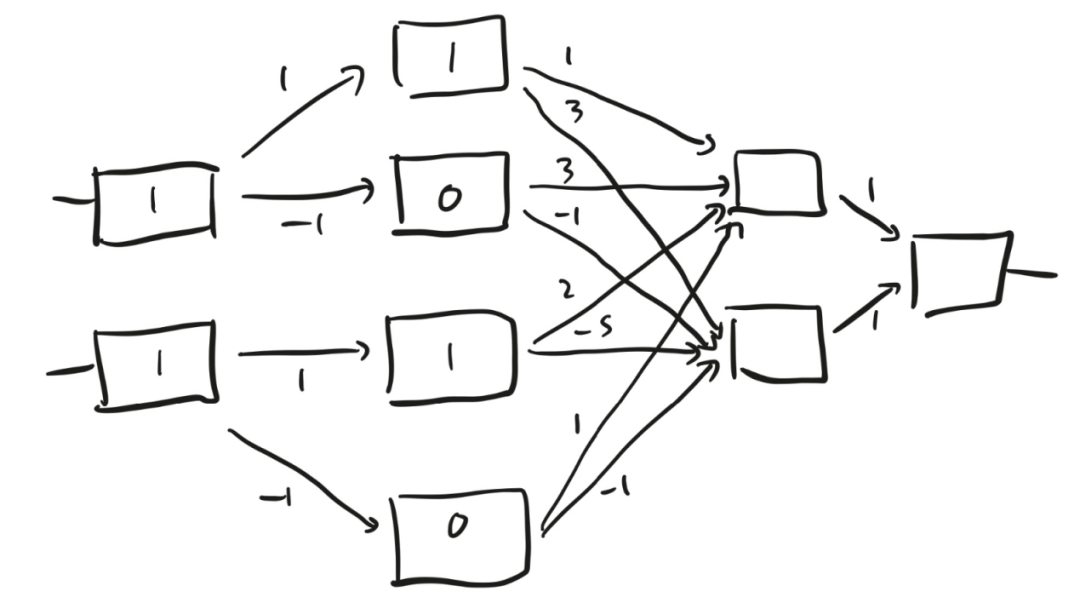
图9
接着看第三层,上面的盒子接收到的数字是1×1+3×0+2×1+1×0=3,下面的盒子接收到的数字是3×1−1×0−5×1−1×0=−2。所以,上面的盒子输出3,下面的盒子未能被触发,输出0。最后,第四层的那个盒子接收到的两个输入之和为1×3+1×0=3。
即使你未关注到这些细节,也没有关系。重要的是,神经网络是一个策略,它接收到两个数字作为输入,并返回一个数字作为输出。如果你改变箭头上的权重,也就是说,如果你转动14个旋钮,就会改变这个策略。图9为你提供了一个十四维空间,让你根据既有的数据从中找出最适合的策略。如果你觉得很难想象出十四维空间的样子,我建议你听从现代神经网络理论的创始人之一杰弗里·辛顿(Geoffrey Hinton)的建议:“想象一个三维空间,并大声对自己说‘这是十四维空间’。所有人应该都能做到这一点。”辛顿来自一个高维空间爱好者家族,他的曾祖父查尔斯在1904年写了一本关于如何想象四维立方体的书,并发明了“超立方体”(tesseract)一词来描述它们。不知道你有没有看过西班牙画家萨尔瓦多·达利的油画作品《受难》,其中就有一个辛顿的超立方体。
图10中这个神经网络的权重已知,如果平面上的点(x, y)位于灰色形状内部,就赋予它一个等于或小于3的值。注意,当点(1, 1)位于灰色形状的边界上时,策略赋予它的值是3。
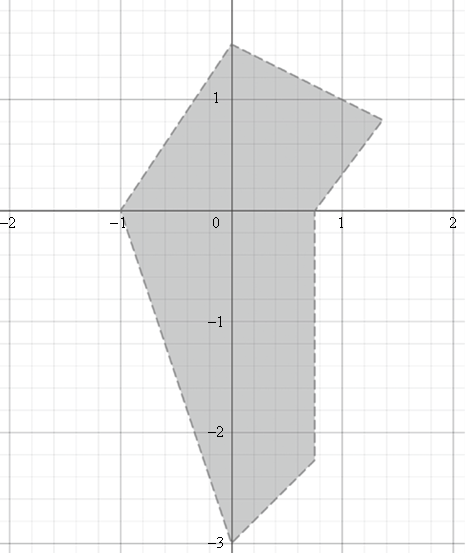
图10
不同的权重会产生不同的形状,虽然不是任意形状。感知机的本质意味着这个形状永远是多边形,即边界由多条线段构成的形状。(前文中不是说这应该是非线性的吗?没错,但感知器是分段线性(piecewise linear)结构,这意味着它在空间的不同区域内满足不同的线性关系。更通用的神经网络可以产生更弯曲的结果。)
如图11所示,假设我用X标记了平面上的一些点,用O标记了其他一些点。我给机器设定的目标是让它习得一个策略:根据我标记的那些点,用X或O为平面上其他未标记的点赋值。也许(希望如此)我可以通过正确设置那14个旋钮得到某个策略,将较大的值赋予所有标记为X的点,而将较小的值赋予所有标记为O的点,以便我对平面上尚未标记的点做出有根据的猜测。如果真有这样的策略,我希望可以通过梯度下降法来习得它:微微转动每个旋钮,看看这个策略在给定例子中的错误分数会降低多少,从中找出效果最佳的那个操作,并付诸实施;重复上述步骤。深度学习中的“深度”仅指神经网络有很多层。每层的盒子个数被称为“宽度”(width),在实践中,这个量可能也很大。但相比“深度学习”,“宽度学习”少了一些专业术语的味道。
可以肯定的是,今天的深度学习网络比上文中的那些示意图要复杂得多,盒子里的函数也比我们讨论过的简单函数要复杂得多。递归神经网络中还包含反馈盒子,就像我的DX21合成器上的“OP4”一样,把自身的输出作为输入。而且,它们的速度明显更快。正如我们所见,神经网络的概念已经存在很长时间了,我记得就在不久前,人们还认为这条路根本走不通。但事实证明,这是一个很好的想法,只不过硬件必须跟上概念的步伐。为快速渲染游戏画面而设计的GPU芯片,后来被证明是快速训练大型神经网络的理想工具,有助于实验人员提升神经网络的深度和宽度。有了现代处理器,你就不必再受限于 14 个旋钮,而可以操控几千、几百万乃至更多的旋钮。GPT-3 生成的英语文本能以假乱真,它使用的神经网络有1750亿个旋钮。
有1750亿个维度的空间听起来的确很大,但和无穷大相比,这个数量又显得微不足道。同样地,与所有可能的策略构成的空间相比,我们正在探索的只是其中很小的一部分。但在实践中,这似乎足以生成看起来像人类创作的文本,就好比DX21的小型网络足以模拟出小号、大提琴和太空霹雳的音色。
这已经非常令人惊讶了,但还有一个更深层次的谜。记住,梯度下降法的理念就是不断转动旋钮,直到神经网络能在训练过的数据点上取得尽可能好的效果。今天的神经网络有许许多多旋钮,所以它们常能做到在训练集上表现完美,把1000幅猫图片中的每一幅都识别为“猫”,而把1000 幅其他图片全部识别为“非猫”。
事实上,有这么多的旋钮可以转动,让训练数据百分之百正确的所有可能策略就会构成一个巨大的空间。事实证明,当神经网络面对它从未见过的图片时,这些策略中的大多数都表现得很糟糕。但是,蠢笨又贪婪的梯度下降过程出现在某些策略中的频率通常高于其他策略,而在实践中,梯度下降法偏爱的那些策略似乎更容易推广到新的例子中。
为什么呢?是什么使得这种特殊形式的神经网络擅长应对各种各样的学习问题?我们在策略空间中搜索的这块微不足道的区域,为什么恰恰就包含了一个好的策略呢?
据我所知,它是一个谜。坦白地说,关于它是不是一个谜的问题,还存在很多争议。我向很多声名显赫的人工智能研究者提问过这个问题,他们回答起来个个口若悬河。其中一些人非常自信地解释了其中的原因,但每个人的说法都不一样。
作者简介:乔丹·埃伦伯格(Jordan Stuart Ellenberg,1971 -),美国数学家,1998年获哈佛大学博士学位,现任威斯康星大学麦迪逊分校John D. MacArthur教授;主要研究方向代数几何和数论。曾获多项科学传播奖项,出版《魔鬼数学》(How Not to Be Wrong),《几何学的力量》(Shape),小说The Grasshopper King等,作品常见于《华尔街日报》《纽约时报》,Slate, Wired等。
本文经授权节选自《几何学的力量》(中信出版社·鹦鹉螺,2023.3)第七章《机器学习如登山》,有删减。
本文来自微信公众号:返朴 (ID:fanpu2019),作者:乔丹·艾伦伯格,编译:胡小锐、钟毅