一、Hadoop框架
Hadoop是目前世界上应用最广泛的大数据工具。Hadoop具有高容错率,且其硬件价格低,可以使用普通PC服务器(个人理解:普通PC服务器的具体形式包括个人计算机等)构成大数据集群。
Hadoop的Map和Reduce函数(Map和Reduce函数是大数据主要编程模型)的计算模式简洁,且开发人员可以通过多种编程语言编写Map和Reduce函数。Hadoop的生态圈(个人理解:此处的生态圈指可以使用Hadoop的开发工具集合)包含大量算法和组件。
Hadoop的数据吞吐量超过其他大数据计算框架,但速度稍慢于其他大数据计算框架。
二、Storm框架
Storm框架采用的是流计算框架(根据网络资料理解:流计算框架可处理实时且持续进入流计算框架数据的计算),也可被称为实时大数据处理框架,在数据处理延时(根据网络资料理解:数据处理延迟的原因是存储或检索数据包需要时间)方面具有较大优势。
但Storm框架只能进行数据处理,不能进行数据存储,因此,Storm框架需借助Hadoop框架的HDFS(分布式文件系统)存储数据。
Storm框架由Twitter(推特)开发,为开源框架,并托管于GitHub(根据百度百科:GitHub是一个面向开源及私有软件项目的托管平台),Storm框架可被免费使用。Storm框架支持的编程语言包括:Java、Ruby、Python。
三、Spark框架
Spark框架包含实时流处理工具,Spark框架没有存储数据功能。Spark框架可以与Hadoop框架集成,代替Hadoop框架的Map和Reduce函数;也可以将Spark框架单独部署集群(根据网络资料理解:部署集群的含义是在集群内的所有电脑或服务器中安装同一应用),但需要借助HDFS等分布式存储系统存储数据。
Spark框架是基于内存的框架,因此,Spark框架的运算速度快,其速度约为Hadoop框架的100倍。
四、Flink框架
(1)与Spark框架相同,Flink框架也是基于内存的实时计算框架。
(2)Flink框架的数据处理速度快于Spark框架的数据处理速度。Flink框架支持毫秒级的流计算,Spark框架支持秒级的流计算。
(3)相比于Spark框架,Flink框架与Hadoop框架具有更好的兼容性。
(4)Flink框架支持API(根据百度百科理解:API一般指应用程序编程接口,可将此处接口理解为服务的传递者。API可使开发人员访问其他系统对外提供的功能接口或服务,且开发人员无需访问该功能接口或服务的源代码或理解该功能接口或服务的内部工作机制细节)接口数量与Spark框架支持API接口数量相近(此句由网络资料总结),但Flink框架对SQL的支持相较于Spark框架对SQL的支持较差。 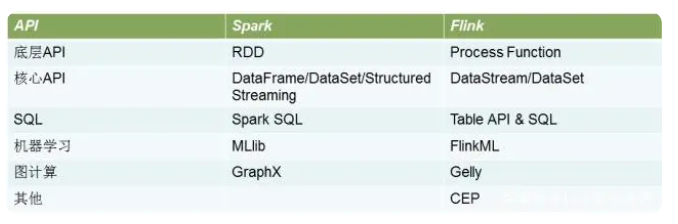
图片来源:网络资料
(5)因为Flink框架较新,使用Flink框架的开发人员较少,所以Flink框架的社区活跃度低于Spark框架,即有关Spark框架的问题更容易得到解答。
五、Yarn架构
Yarn架构属于Hadoop2.0的分支。如图一所示,Yarn架构处于HDFS和MapReduce之间。
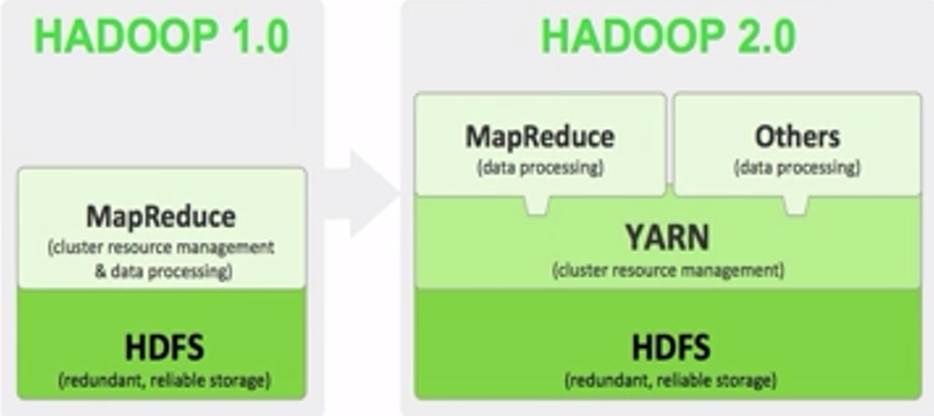
图一,图片来源:学堂在线《大数据导论》
Yarn架构主要由ResourceManager、NodeManager、ApplicationMaster(根据网络资料:ApplicationMaster负责与ResourceManager协商资源,并与NodeManager协同来执行和监控Container) 、Container(根据网络资料:Container可被理解为单个节点RAM、CPU、磁盘的集合)组件构成。
Yarn架构的结构是master/slave结构(master的中文含义是主人,slave的中文含义是奴隶,master/slave结构即为主从结构)。如图二所示,ResourceManager是master,即主节点;NodeManager是slave,即从节点。 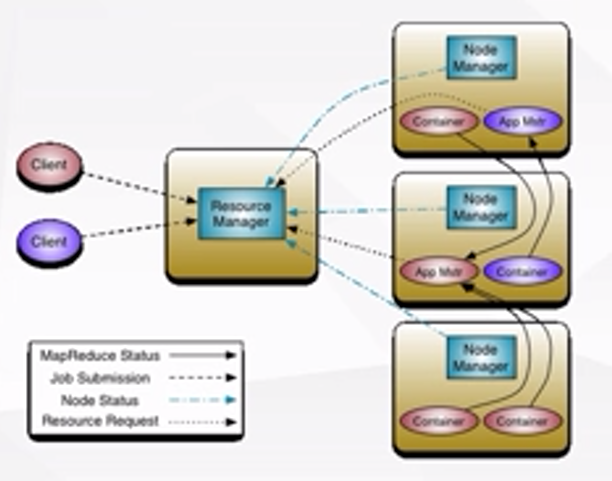
图二,图片来源:学堂在线《大数据导论》
审核编辑:刘清