字节数据中台 DataLeap 的 Data Catalog 系统通过接收 MQ 中的近实时消息来同步部分元数据。Apache Atlas 对于实时消息的消费处理不满足性能要求,内部使用 Flink 任务的处理方案在 ToB 场景中也存在诸多限制,所以团队自研了轻量级异步消息处理框架,很好的支持了字节内部和火山引擎上同步元数据的诉求。本文定义了需求场景,并详细介绍框架的设计与实现。
1. 背景
1.1 动机
字节数据中台 DataLeap 的 Data Catalog 系统基于 Apache Atlas 搭建,其中 Atlas 通过 Kafka 获取外部系统的元数据变更消息。在开源版本中,每台服务器支持的 Kafka Consumer 数量有限,在每日百万级消息体量下,经常有长延时等问题,影响用户体验。
在 2020 年底,我们针对 Atlas 的消息消费部分做了重构,将消息的消费和处理从后端服务中剥离出来,并编写了 Flink 任务承担这部分工作,比较好的解决了扩展性和性能问题。然而,到 2021 年年中,团队开始重点投入私有化部署和火山公有云支持,对于 Flink 集群的依赖引入了可维护性的痛点。
在仔细的分析了使用场景和需求,并调研了现成的解决方案后,我们决定投入人力自研一个消息处理框架。当前这个框架很好的支持了字节内部以及 ToB 场景中 Data Catalog 对于消息消费和处理的场景。
本文会详细介绍框架解决的问题,整体的设计,以及实现中的关键决定。
1.2 需求定义
使用下面的表格将具体场景定义清楚。
需求维度 | 需求描述 |
吞吐量 | 每日百万级别,每秒峰值>100 |
服务质量(QoS) | 至少一次 |
延迟消息 | 支持将消息标记为延迟处理,最高延迟 1 min |
重试 | 自动对处理失败消息重试,重试次数可定义 |
并行与顺序处理 | Partition 内部支持按照某个 Key 重新分组,不同 Key 之间接受并行,同一个 Key 要求顺序处理 |
消息处理时间 | 不同类型的消息,处理时间会有较大差别,从< 1 s~1 min |
封装 | 确保不丢消息的前提下,依赖框架做 Offset 的提交,业务侧只需要编写消息的处理逻辑;另外,将系统状态以 Metric 方式暴露 |
轻量 | 支持与后端服务混合部署,不引入额外的维护成本 |
1.3 相关工作
在启动自研之前,我们评估了两个比较相关的方案,分别是 Flink 和 Kafka Streaming。
Flink 是我们之前生产上使用的方案,在能力上是符合要求的,最主要的问题是长期的可维护性。在公有云场景,那个阶段 Flink 服务在火山云上还没有发布,我们自己的服务又有严格的时间线,所以必须考虑替代;在私有化场景,我们不确认客户的环境一定有 Flink 集群,即使部署的数据底座中带有 Flink,后续的维护也是个头疼的问题。另外一个角度,作为通用流式处理框架,Flink 的大部分功能其实我们并没有用到,对于单条消息的流转路径,其实只是简单的读取和处理,使用 Flink 有些“杀鸡用牛刀”了。
另外一个比较标准的方案是 Kafka Streaming。作为 Kafka 官方提供的框架,对于流式处理的语义有较好的支持,也满足我们对于轻量的诉求。最终没有采用的主要考虑点是两个:
- 对于 Offset 的维护不够灵活:我们的场景不能使用自动提交(会丢消息),而对于同一个 Partition 中的数据又要求一定程度的并行处理,使用 Kafka Streaming 的原生接口较难支持。
- 与 Kafka 强绑定:大部分场景下,我们团队不是元数据消息队列的拥有者,也有团队使用 RocketMQ 等提供元数据变更,在应用层,我们希望使用同一套框架兼容。
2. 设计
2.1 概念说明
- MQ Type:Message Queue 的类型,比如 Kafka与RocketMQ。后续内容以 Kafka 为主,设计一定程度兼容其他 MQ。
- Topic:一批消息的集合,包含多个 Partition,可以被多个 Consumer Group消费。
- Consumer Group:一组 Consumer,同一 Group 内的 Consumer 数据不会重复消费。
- Consumer:消费消息的最小单位,属于某个 Consumer Group。
- Partition:Topic 中的一部分数据,同一 Partition 内消息有序。同一 Consumer Group 内,一个 Partition 只会被其中一个 Consumer 消费。
- Event:由 Topic 中的消息转换而来,部分属性如下。
- Event Type:消息的类型定义,会与 Processor 有对应关系;
- Event Key:包含消息 Topic、Partition、Offset 等元数据,用来对消息进行 Hash 操作;
- Processor:消息处理的单元,针对某个 Event Type 定制的业务逻辑。
- Task:消费消息并处理的一条 Pipeline,Task 之间资源是相互独立的。
2.2 框架架构
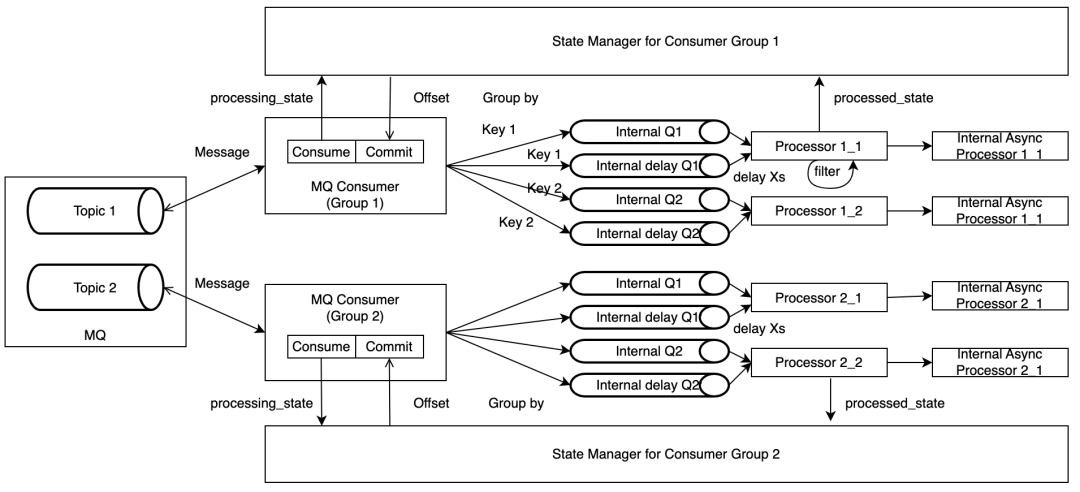
整个框架主要由 MQ Consumer, Message Processor 和 State Manager 组成。
- MQ Consumer:负责从Kafka Topic拉取消息,并根据 Event Key 将消息投放到内部队列,如果消息需要延时消费,会被投放到对应的延时队列;该模块还负责定时查询 State Manager 中记录的消息状态,并根据返回提交消息 Offset;上报与消息消费相关的 Metric。
- Message Processor:负责从队列中拉取消息并异步进行处理,它会将消息的处理结果更新给 State Manager,同时上报与消息处理相关的 Metric。
- State Manager:负责维护每个 Kafka Partition 的消息状态,并暴露当前应提交的 Offset 信息给 MQ Consumer。
3. 实现
3.1 线程模型
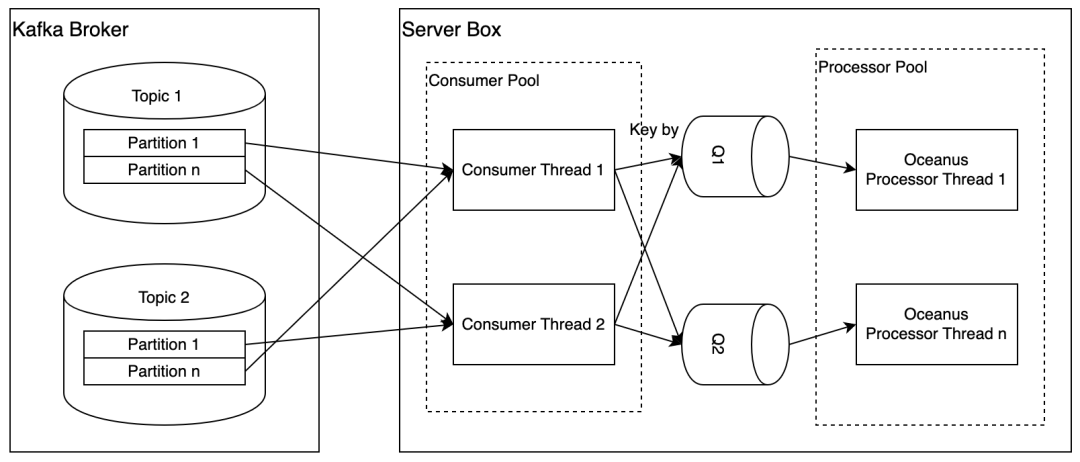
每个 Task 可以运行在一台或多台实例,建议部署到多台机器,以获得更好的性能和容错能力。
每台实例中,存在两组线程池:
- Consumer Pool:负责管理 MQ Consumer Thread 的生命周期,当服务启动时,根据配置拉起一定规模的线程,并在服务关闭时确保每个 Thread 安全退出或者超时停止。整体有效 Thread 的上限与 Topic 的 Partition 的总数有关。
- Processor Pool:负责管理 Message Processor Thread 的生命周期,当服务启动时,根据配置拉起一定规模的线程,并在服务关闭时确保每个 Thread 安全退出或者超时停止。可以根据 Event Type 所需要处理的并行度来灵活配置。
两类 Thread 的性质分别如下:
- Consumer Thread:每个 MQ Consumer 会封装一个 Kafka Consumer,可以消费 0 个或者多个 Partition。根据 Kafka 的机制,当 MQ Consumer Thread 的个数超过 Partition 的个数时,当前 Thread 不会有实际流量。
- Processor Thread:唯一对应一个内部的队列,并以 FIFO 的方式消费和处理其中的消息。
3.2 StateManager
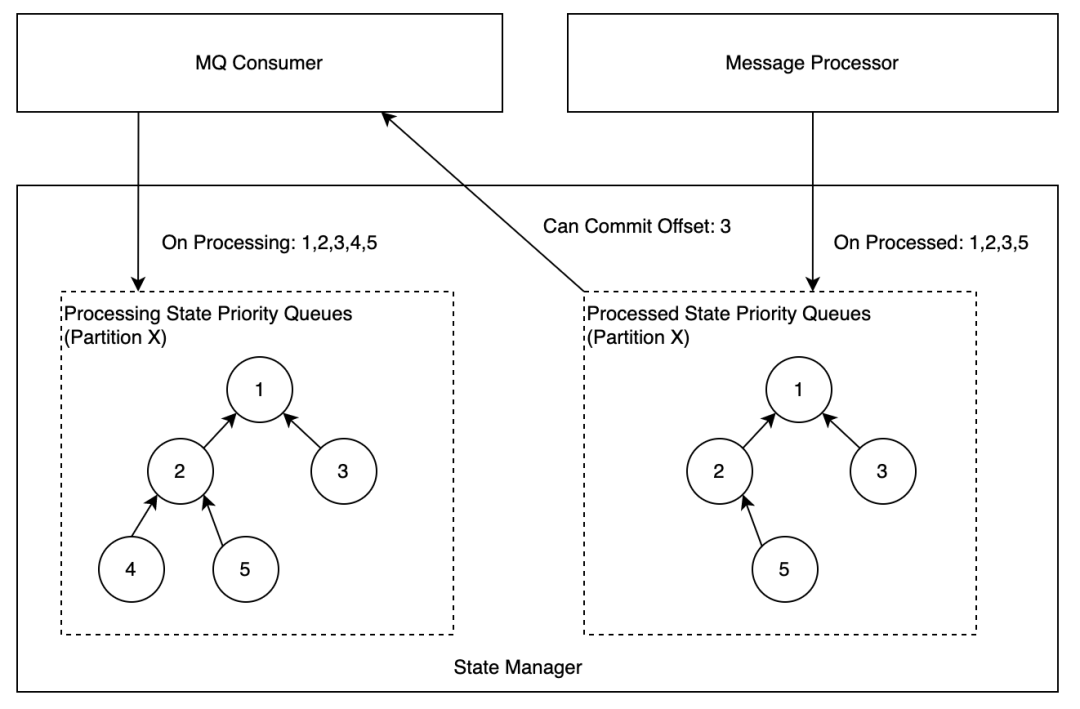
在 State Manager 中,会为每个 Partition 维护一个优先队列(最小堆),队列中的信息是 Offset,两个优先队列的职责如下:
- 处理中的队列:一条消息转化为 Event 后,MQ Consumer 会调用 StateManager 接口,将消息 Offset 插入该队列。
- 处理完的队列:一条消息处理结束或最终失败,Message Processor 会调用 StateManager 接口,将消息 Offset 插入该队列。
MQ Consumer 会周期性的检查当前可以 Commit 的 Offset,情况枚举如下:
- 处理中的队列堆顶 < 处理完的队列堆顶或者处理完的队列为空:代表当前消费回来的消息还在处理过程中,本轮不做 Offset 提交。
- 处理中的队列堆顶 = 处理完的队列堆顶:表示当前消息已经处理完,两边同时出队,并记录当前堆顶为可提交的 Offset,重复检查过程。
- 处理中的队列堆顶 > 处理完的队列堆顶:异常情况,通常是数据回放到某些中间状态,将处理完的队列堆顶出堆。
注意:当发生 Consumer 的 Rebalance 时,需要将对应 Partition 的队列清空
3.3 KeyBy 与 Delay Processing 的支持
因源头的 Topic 和消息格式有可能不可控制,所以 MQ Consumer 的职责之一是将消息统一封装为 Event。
根据需求,会从原始消息中拼装出 Event Key,对 Key 取 Hash 后,相同结果的 Event 会进入同一个队列,可以保证分区内的此类事件处理顺序的稳定,同时将消息的消费与处理解耦,支持增大内部队列数量来增加吞吐。
Event 中也支持设置是否延迟处理属性,可以根据 Event Time 延迟固定时间后处理,需要被延迟处理的事件会被发送到有界延迟队列中,有界延迟队列的实现继承了 DelayQueue,限制 DelayQueue 长度, 达到限定值入队会被阻塞。
3.4 异常处理
Processor 在消息处理过程中,可能遇到各种异常情况,设计框架的动机之一就是为业务逻辑的编写者屏蔽掉这种复杂度。Processor 相关框架的逻辑会与 State Manager 协作,处理异常并充分暴露状态。比较典型的异常情况以及处理策略如下:
- 处理消息失败:自动触发重试,重试到用户设置的最大次数或默认值后会将消息失败状态通知 State Manager。
- 处理消息超时:超时对于吞吐影响较大,且通常重试的效果不明显,因此当前策略是不会对消息重试,直接通知 State Manager 消息处理失败。
- 处理消息较慢:上游 Topic 存在 Lag,Message Consumer 消费速率大于 Message Processor 处理速率时,消息会堆积在队列中,达到队列最大长度, Message Consumer 会被阻塞在入队操作,停止拉取消息,类似 Flink 框架中的背压。
3.5 监控
为了方便运维,在框架层面暴露了一组监控指标,并支持用户自定义 Metrics。其中默认支持的 Metrics 如下表所示:
监控类别 | 监控指标 |
Message Consumer | Consumer Lag |
Rebalance rate | |
Deserialize QPS | |
Consumer heartbeat | |
Message Enqueue Time | |
Message Processor | Process QPS |
Process time | |
Internal Queue | Queue length |
4. 线上运维 Case 举例
实际生产环境运行时,偶尔需要做些运维操作,其中最常见的是消息堆积和消息重放。
对于 Conusmer Lag 这类问题的处理步骤大致如下:
- 查看 Enqueue Time,Queue Length 的监控确定服务内队列是否有堆积。
- 如果队列有堆积,查看 Process Time 指标,确定是否是某个 Processor 处理慢,如果是,根据指标中的 Tag 确定事件类型等属性特征,判断业务逻辑或者 Key 设置是否合理;全部 Processor 处理慢,可以通过增加 Processor 并行度来解决。
- 如果队列无堆积,排除网络问题后,可以考虑增加 Consumer 并行度至 Topic Partition 上限。
消息重放被触发的原因通常有两种,要么是业务上需要重放部分数据做补全,要么是遇到了事故需要修复数据。为了应对这种需求,我们在框架层面支持了根据时间戳重置 Offset 的能力。具体操作时的步骤如下:
- 使用服务侧暴露的 API,启动一台实例使用新的 Consumer GroupId: {newConsumerGroup} 从某个 startupTimestamp 开始消费。
- 更改全部配置中的 Consumer GroupId 为 {newConsumerGroup}。
- 分批重启所有实例。
5. 总结
为了解决字节数据中台 DataLeap 中 Data Catalog 系统消费近实时元数据变更的业务场景,我们自研了轻量级消息处理框架。当前该框架已在字节内部生产环境稳定运行超过 1 年,并支持了火山引擎上的数据地图服务的元数据同步场景,满足了我们团队的需求。
下一步会根据优先级排期支持 RocketMQ 等其他消息队列,并持续优化配置动态更新,监控报警,运维自动化等方面。